



これはラオスにいたときに、ラオスの公用語ラオ語の発音練習のために作ってみました。Google翻訳に音声認識があるのですが、GoogleCloudPlatformに様々なサービスがあるので使ってみたいなと思っていたのでSpeech-To-Textのサービスを試してみました。
言語習得が本当に苦手で、今でも苦戦していますが。。。まったく聞き取れない音、違いが分からない発音も多く、発音の練習何度もしていましたが結局は上達はしません。日本語の発音を色々調べていると、日本語の【ん】の文字は1つでも発音は数種類あり、例えば、せんべい、しんばし、しんじゅく、とんかつ、かんり 5つとも発音や舌の動きや唇の状態など比べるとわかるかと思いますが、きちんと教わっていないのに子供のころの感性はすごいなと改めて思います。
今回の開発環境は以下になります。
・OS:Window10
・言語:Python3.6
・統合開発環境:Pycharm
・API:Google Cloud Platform(Googleアカウントが必要です。)
※GoogleCloudPlatformのアカウント作成利用手続きは省略します。30日間無料がありますのでそちらで利用してみてください。
1.Speech-To-TextAPIを有効にする
1.GoogleCloudPlatformのAPIとサービスからライブラリを選択
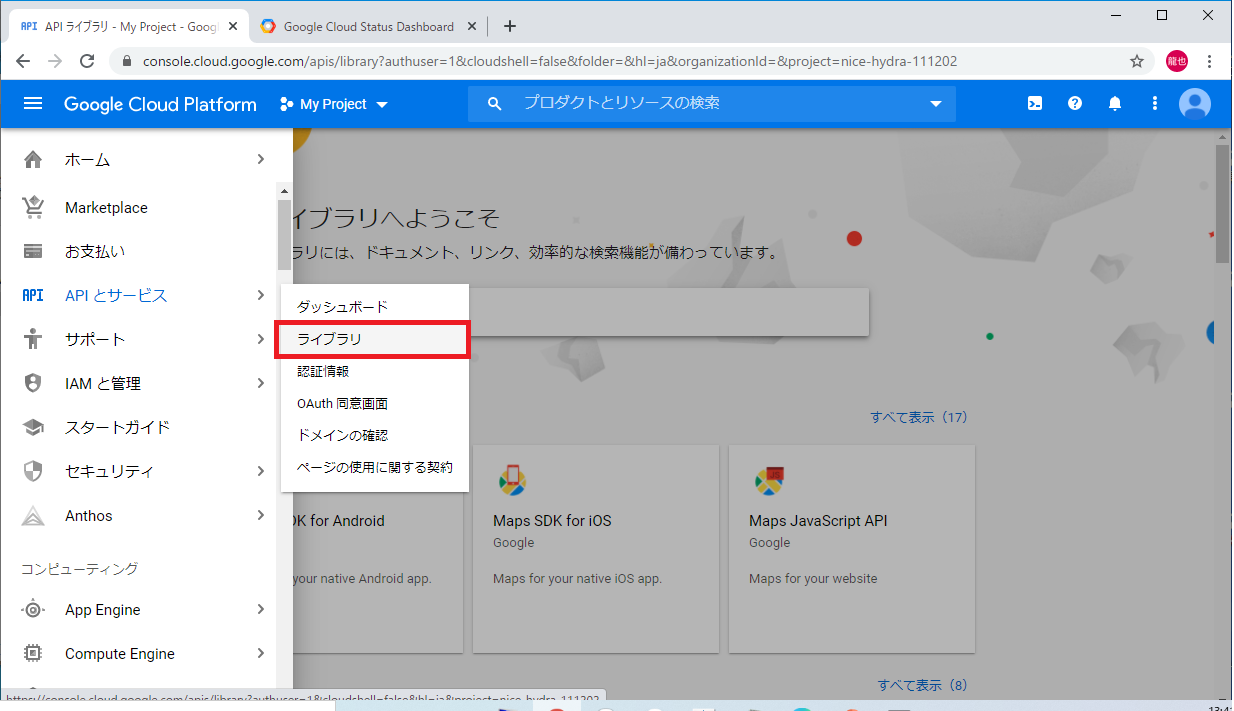
2.サービス名にSpeech-to-Textを入力するか、機械学習の項目から選択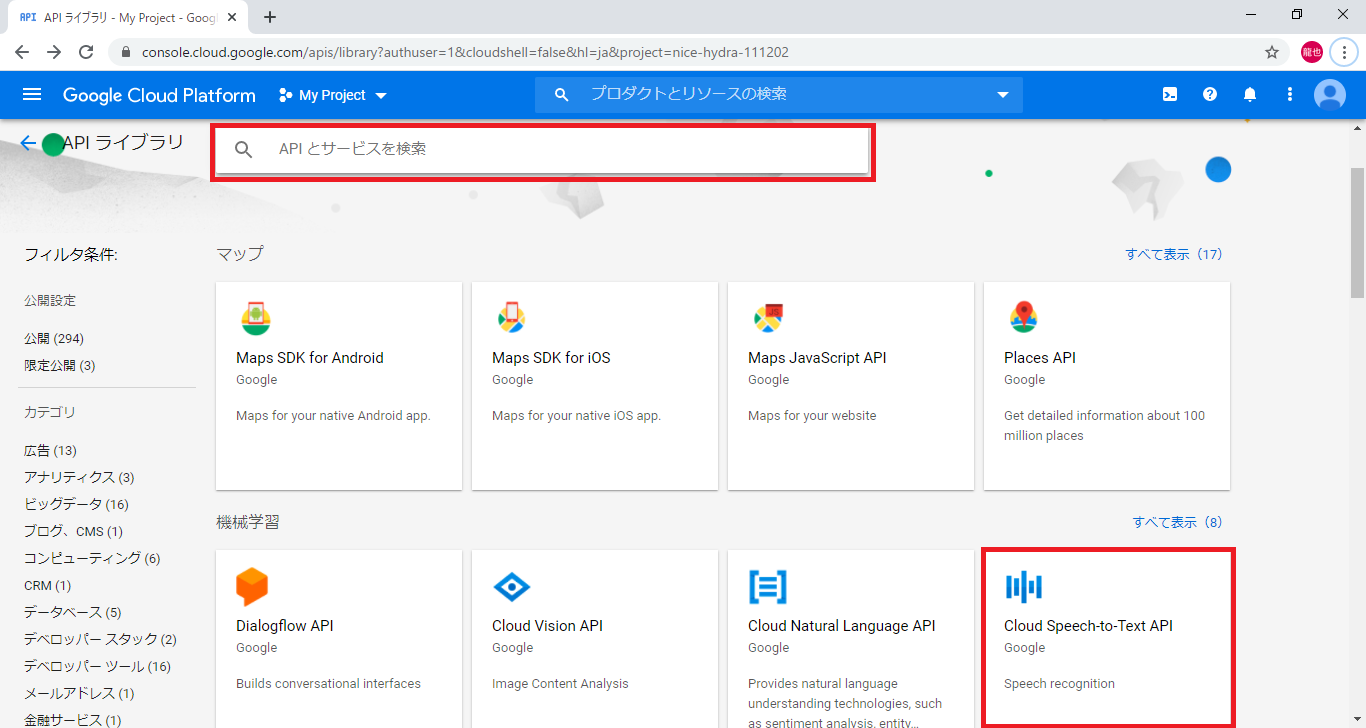
3.有効にするを選択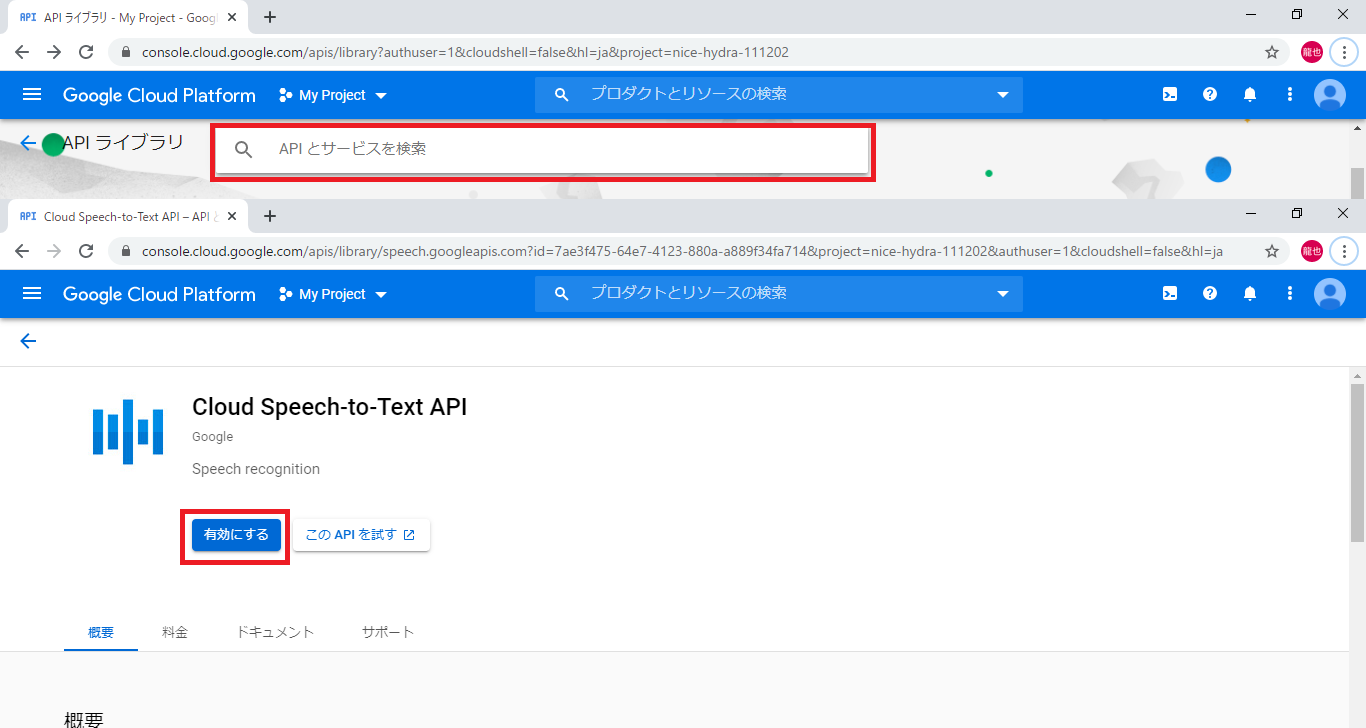
4.プロジェクトの選択が表示されたら、そのまま完了ボタン選択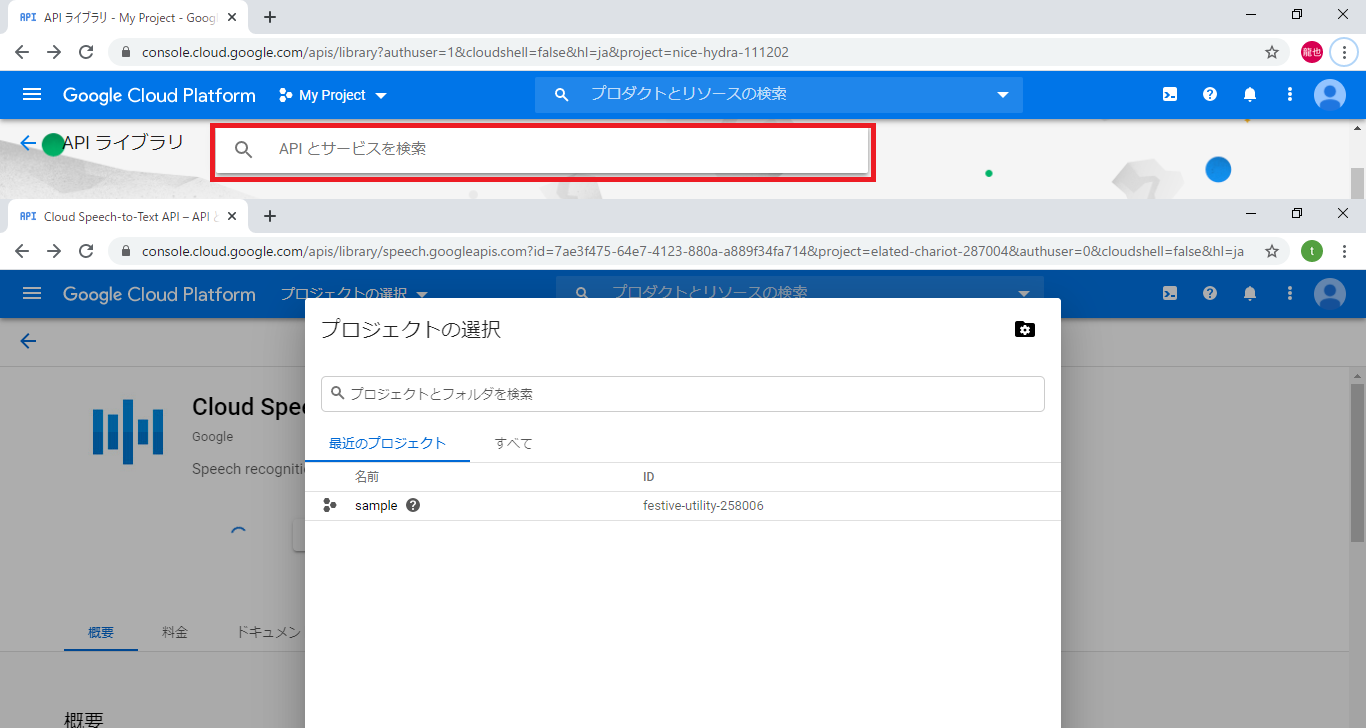
5.左側の認証情報を選択し APIとサービスの認証情報を選択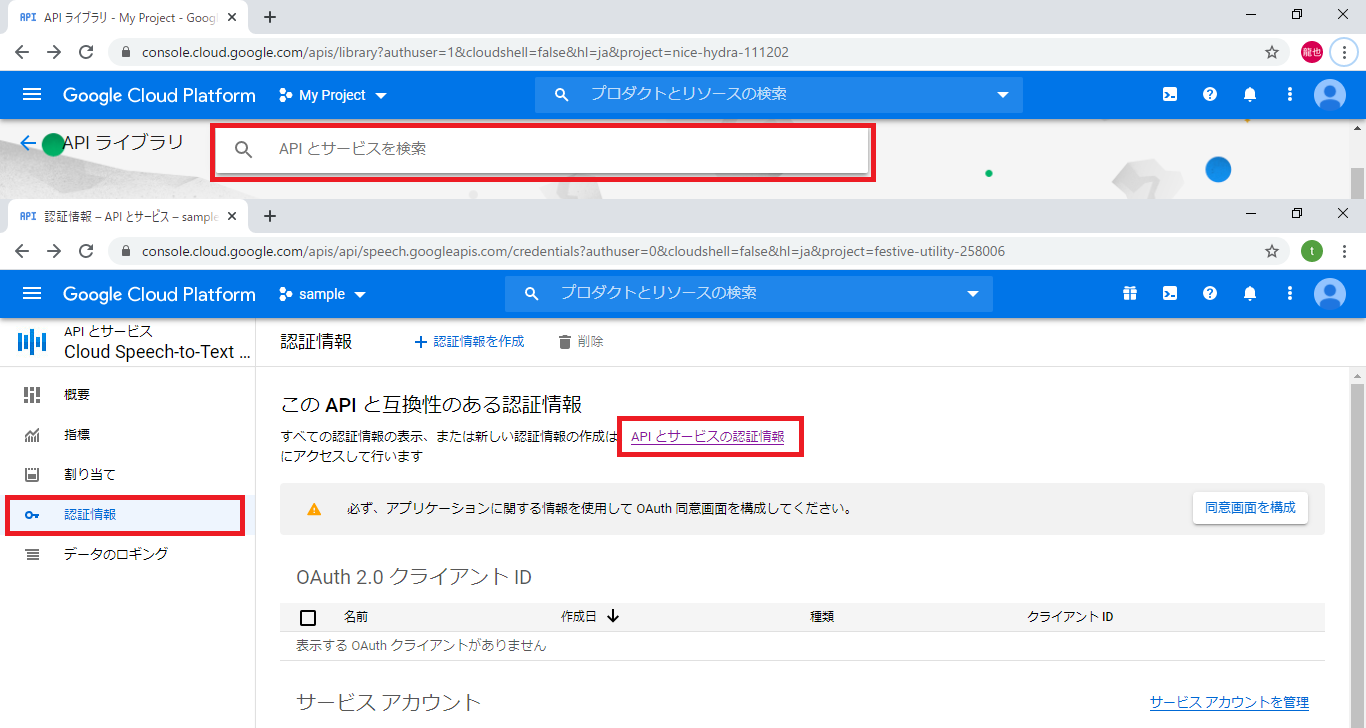
6.次の画面に変わったら、作成ボタンを選択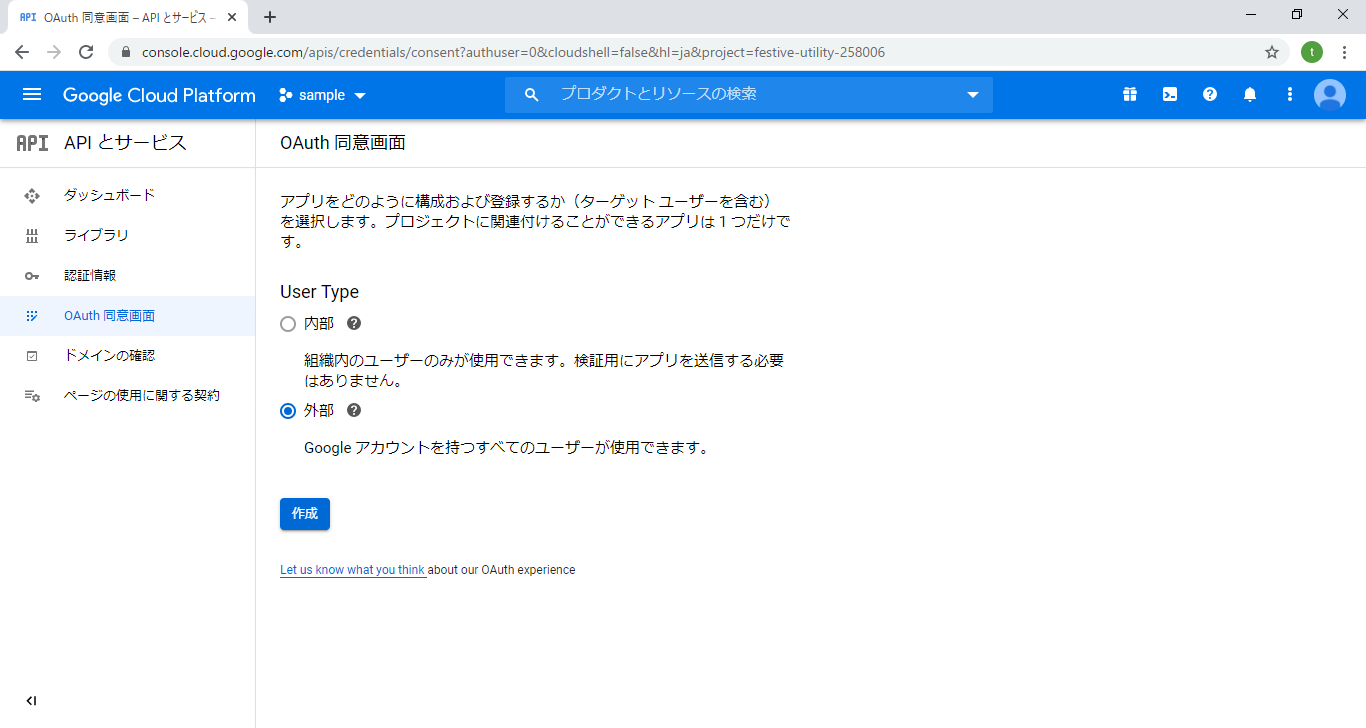
7.アプリケーション名を入力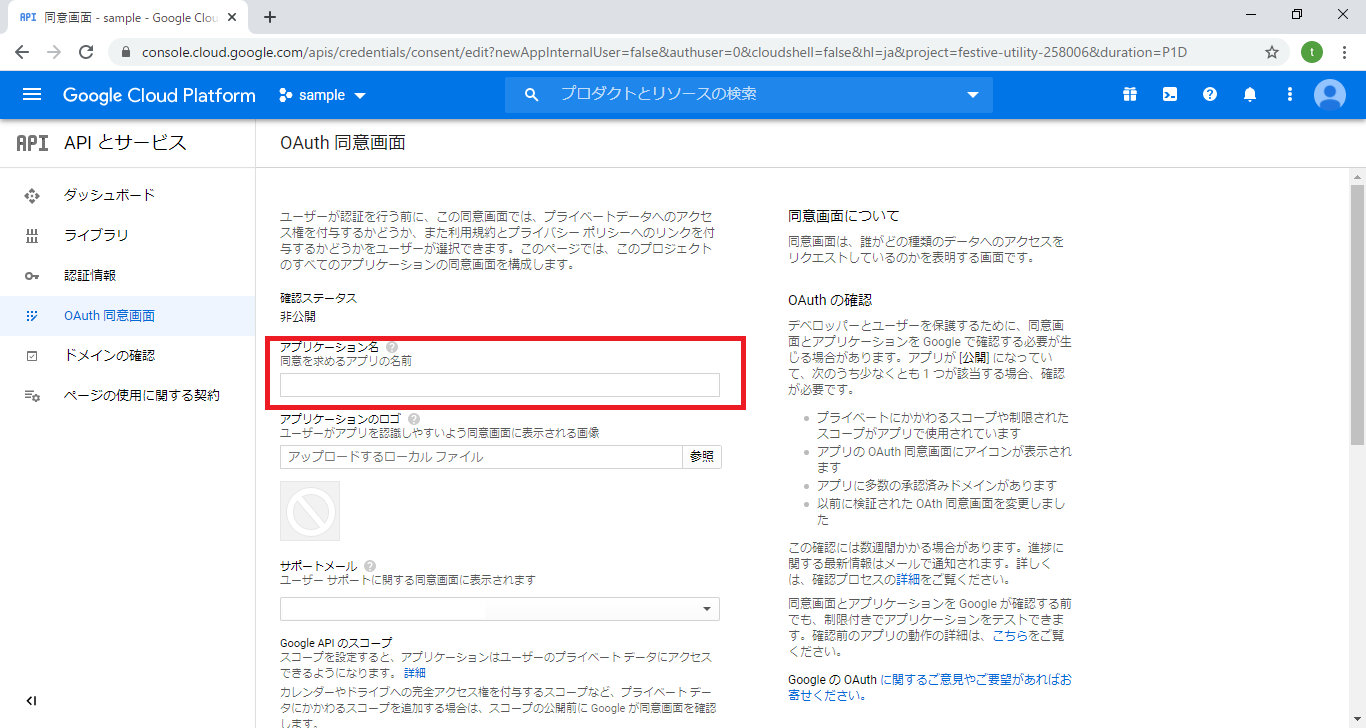
8.以下のように同意画面が表示されたら完了です。(今回はLaotextとしました。)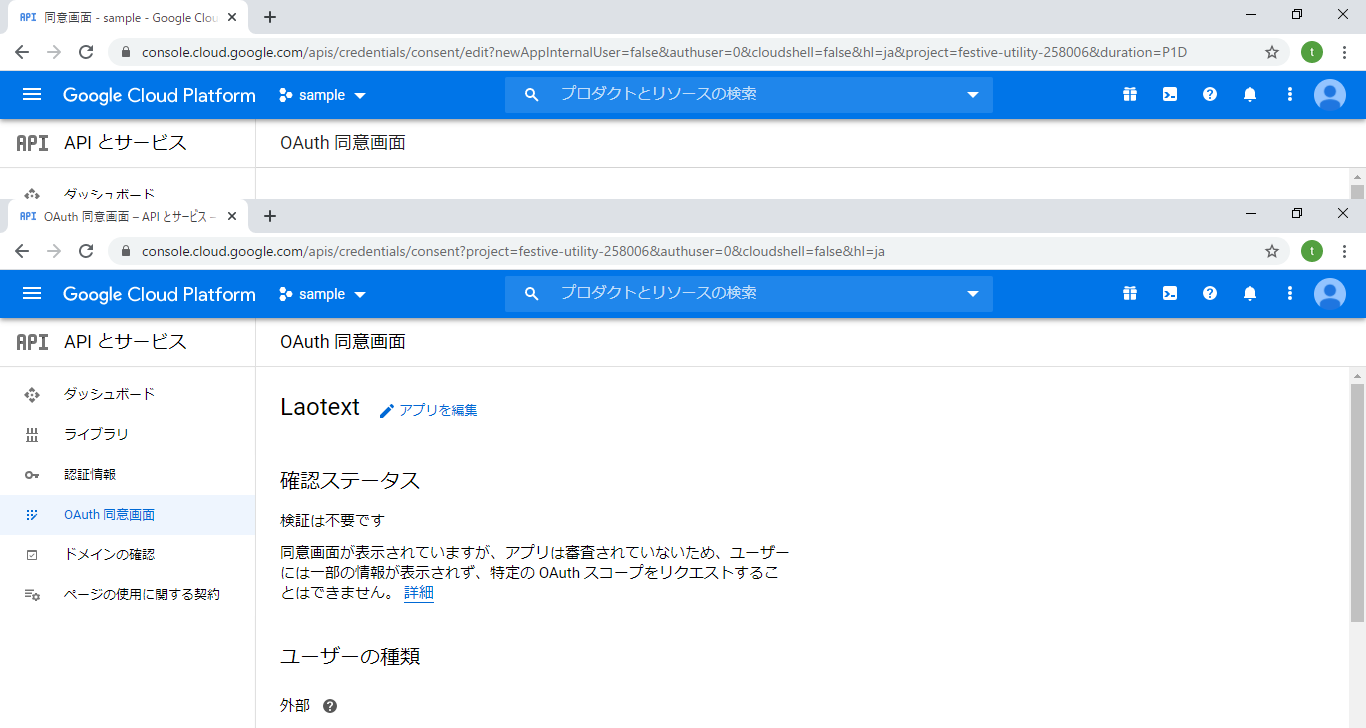
2.Python環境を作成
必要なライブラリをインストールします。コマンドプロンプトを立ち上げて、以下のモジュールをインストール
pip3 install google-cloud-pubsub
pip3 install oauth2client
pip3 install wheel
pip install pipwin
pip install pyaudio
3.GoogleAPI認証処理
Google Cloud SDK Installerで認証処理を実施します。
以下のサイトからファイルをダウンロードしてインストールしてください。
説明は省略します。https://cloud.google.com/sdk/install
4.開発コード
開発コードは、GoogleCloudPlatformにありますが、コピーをのせておきます。
import re
import sys
from google.cloud import speech
from google.cloud.speech import enums
from google.cloud.speech import types
import pyaudio
from six.moves import queue
# Audio recording parameters
RATE = 16000
CHUNK = int(RATE / 10) # 100ms
class MicrophoneStream(object):
"""Opens a recording stream as a generator yielding the audio chunks."""
def __init__(self, rate, chunk):
self._rate = rate
self._chunk = chunk
# Create a thread-safe buffer of audio data
self._buff = queue.Queue()
self.closed = True
def __enter__(self):
self._audio_interface = pyaudio.PyAudio()
self._audio_stream = self._audio_interface.open(
format=pyaudio.paInt16,
# The API currently only supports 1-channel (mono) audio
# https://goo.gl/z757pE
channels=1, rate=self._rate,
input=True, frames_per_buffer=self._chunk,
# Run the audio stream asynchronously to fill the buffer object.
# This is necessary so that the input device's buffer doesn't
# overflow while the calling thread makes network requests, etc.
stream_callback=self._fill_buffer,
)
self.closed = False
return self
def __exit__(self, type, value, traceback):
self._audio_stream.stop_stream()
self._audio_stream.close()
self.closed = True
# Signal the generator to terminate so that the client's
# streaming_recognize method will not block the process termination.
self._buff.put(None)
self._audio_interface.terminate()
def _fill_buffer(self, in_data, frame_count, time_info, status_flags):
"""Continuously collect data from the audio stream, into the buffer."""
self._buff.put(in_data)
return None, pyaudio.paContinue
def generator(self):
while not self.closed:
# Use a blocking get() to ensure there's at least one chunk of
# data, and stop iteration if the chunk is None, indicating the
# end of the audio stream.
chunk = self._buff.get()
if chunk is None:
return
data = [chunk]
# Now consume whatever other data's still buffered.
while True:
try:
chunk = self._buff.get(block=False)
if chunk is None:
return
data.append(chunk)
except queue.Empty:
break
yield b''.join(data)
def listen_print_loop(responses):
"""Iterates through server responses and prints them.
The responses passed is a generator that will block until a response
is provided by the server.
Each response may contain multiple results, and each result may contain
multiple alternatives; for details, see https://goo.gl/tjCPAU. Here we
print only the transcription for the top alternative of the top result.
In this case, responses are provided for interim results as well. If the
response is an interim one, print a line feed at the end of it, to allow
the next result to overwrite it, until the response is a final one. For the
final one, print a newline to preserve the finalized transcription.
"""
num_chars_printed = 0
for response in responses:
if not response.results:
continue
# The `results` list is consecutive. For streaming, we only care about
# the first result being considered, since once it's `is_final`, it
# moves on to considering the next utterance.
result = response.results[0]
if not result.alternatives:
continue
# Display the transcription of the top alternative.
transcript = result.alternatives[0].transcript
# Display interim results, but with a carriage return at the end of the
# line, so subsequent lines will overwrite them.
#
# If the previous result was longer than this one, we need to print
# some extra spaces to overwrite the previous result
overwrite_chars = ' ' * (num_chars_printed - len(transcript))
if not result.is_final:
sys.stdout.write(transcript + overwrite_chars + '\r')
sys.stdout.flush()
num_chars_printed = len(transcript)
else:
print(transcript + overwrite_chars)
# Exit recognition if any of the transcribed phrases could be
# one of our keywords.
if re.search(r'\b(exit|quit)\b', transcript, re.I):
print('Exiting..')
break
num_chars_printed = 0
def main():
# See http://g.co/cloud/speech/docs/languages
# for a list of supported languages.
#language_code = 'en-US' # a BCP-47 language tag
language_code = 'lo-LA'
client = speech.SpeechClient()
config = types.RecognitionConfig(
encoding=enums.RecognitionConfig.AudioEncoding.LINEAR16,
sample_rate_hertz=RATE,
language_code=language_code)
streaming_config = types.StreamingRecognitionConfig(
config=config,
interim_results=True)
with MicrophoneStream(RATE, CHUNK) as stream:
audio_generator = stream.generator()
requests = (types.StreamingRecognizeRequest(audio_content=content)
for content in audio_generator)
responses = client.streaming_recognize(streaming_config, requests)
# Now, put the transcription responses to use.
listen_print_loop(responses)
if __name__ == '__main__':
main()
今回は、ラオ語で試すので137行目のlanguage_code = 'en-US' # a BCP-47 language tag
の前にコメントアウトの#を追加して、下の行(138行目)に
language_code = 'lo-LA'
認識させたい言語は、以下にありますので確認してみてください。初期値は英語です。
https://cloud.google.com/speech-to-text/docs/languages
5.実践
Pycharmは、以下の状態で構成されています。赤枠がファイル一覧、青枠がプログラムソース、緑枠が実行できるTerminalになります。
実際にラオス語で話してみました。
一応、反応は少し待ちますがきちんと文字起こし出来ました。
ちなみに1行目の【サバイディー】は、挨拶です。2行目の【ヘッドニャンユー】は何しているの?3行目は1~5の数字になります。
6.まとめ
いかがでしょうか?Speech-to-Text以外にも色々使えそうなAPIがそろっているので、組み合わせた形でも面白いものが出来そうです。
議事録ツールはありそうなので、会議の文字起こしをしてどの言葉が多く使われているなど可視化するとか、何か他のAPIも試して紹介してみたいと思います。
それでは、また次回。
-3.png)

