



前回はPythonを使って定期的に写真を取るまで紹介しました。
その取得した写真を振り分けるところから説明をします。
1.画像振分け
一番悩みどころが、車体全体が写っていない場合の処理でした。後で説明しますが、撮った画像から車の座標をもとに機械学習させるのですが、車の一部だけが写っていることも多く”車っぽい”ものがあると、それも車として認識してしまうので、今回は車全体が写っていないものはNGの写真として処理させることにしました。そのほか軽自動車、普通車、トラック、バスなど車の形などあり、まだどうするか悩みどころです。とりあえずスタートしたので開発途中で考えることが多かったです。
以下の内容が判断が厳しくさせる内容でした。
・車の一部しか映ってない
・車体の大きさ
・地面の光と影など
以下の写真のように、道路の日の当たっている部分や影や車の一部などの画像を分ける判断が必要でした。

2.車の座標データを作成
撮った写真をNeoTrainingAssistというツールを使って画像の車の座標リストを作成します。本来は、以下のように画像1枚づつファイル名、認識したい物体の個数、X座標、Y座標、横の長さ、縦の長さを指定します。
<車の座標リストの内容>
ディレクトリ名\ファイル名.jpg 1 233 200 137 78←こんな感じです。
これをNeoTrainingAssistは、以下の画面のようにクリックしてドラッグするだけで、枠線が表示されるので問題なければOKで次々と作業が簡単にできます。
これが無かったら相当大変でした。
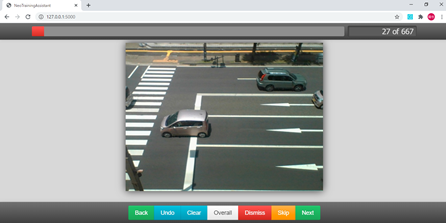
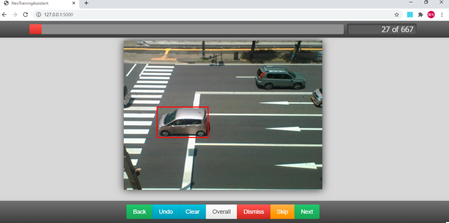
不正解ファイルもリストが必要で、不正解ファイルは画像のディレクトリ+ファイル名を示したファイルのみの記述になります。
ディレクトリ名\camera0.jpg
※これはコマンドでファイル作成が楽かと思います。
3.サンプルファイルの生成
用意できたら、以下のコマンドで、現在の画像からサンプル画像を増やすことができます。これは実際の画像ファイルを増やすのではなくvecファイルというものに書き込むもののようです。
正解画像とリストファイル(positive.dat)、不正解画像とリストファイル(negative.dat)
を用意できたら、以下のコマンドで分類器(カスケード)の作成になります。
実行すると、cascadeフォルダにcascade.xmlというファイルが作成できるので、これで分配器が作成完了となります。
4.実践
実際の画像2447枚を3000枚までサンプルを追加して、不正解画像は1874枚で処理しました。結果は、こんな感じです。
まだまだ難しいというところです。車両が通るたびに捉えてますが、安定していません。
実際、やってみるとどういう影響があるのか色々と分かることが多かったです。
ちなみに、背景などごちゃごちゃしない状態で、同じ物体でとってみました。
画像は正解10枚程度で不正解5枚くらいです。
少ない枚数の割には、ドローンの認識が良いかなと思います。認識したいものが同一で限りなく近い事、背景などに余計なものが無い状態であればかなりの精度で認識できるのかと思ってます。今は開発を中断していますが、再開するきっかけで他のライブラリやGoogleCoraborateなどGPUで開発出来る環境など新しい進捗がありましたら記事にしたいと思います。
それでは、また次回。
-3.png)

